|
 |
||||||||||||||||||||||
|
| ||||||||||||||||||||||
|
安価&大容量ディスクサブシステムに欠かせないデータ保護技術「RAID 6」 |
||||||||||||||||||||||
|
|
||||||||||||||||||||||
|
| ||||||||||||||||||||||
|
HDDの使用効率とアクセス性能のバランスに優れたRAID 5。このため、多くのディスクサブシステムは、HDDの障害に備えてRAID 5でデータ保護を行っている。しかし、ディスクサブシステムを構成するHDDの記憶容量と台数が増え、しかもコスト削減を目的としてATA HDDを搭載するようになり、RAID 5では十分なデータ保護を行えないケースが見受けられるようになった。また、SANやNASを通じて1台のディスクサブシステムを複数のサーバーから共有する形が一般化しており、ディスクサブシステムのデータ損失が複数のサーバーに影響を与えてしまう。 そこで、こうした数々の問題に立ち向かうために、RAID 5よりも強固なデータ保護を可能にするRAID 6をディスクサブシステムに実装するケースが増えてきた。今回は、RAID 5で十分にデータ保護を行えない理由を定量的に説明した上で、今回のターゲットであるRAID 6の仕組みとRAID 6を実装したディスクサブシステムの動向を取り上げる。 ■ degraded modeで発生するトラブルにまったく対応できないRAID 5 RAID 5は、複数のHDDに対してデータとパリティをブロック単位で分散書き込みする手法だ。このため、RAIDグループを構成するHDDのうち1台が故障すると、データの冗長性が完全に失われてしまう。この信頼性が低下した状態(degraded mode)でそのまま放置しておくと非常に危険だ。そこで、速やかに故障したHDDを新しいものに入れ替え、RAIDグループの再構築を実行しなければならない。ただし、ストレージ管理者がその場にいなければ即座に対応できないことから、予備のホットスペアディスクを搭載できる製品が一般的だ。これにより、RAIDグループを構成するHDDのうち1台が故障したら、ストレージ管理者の手を介することなく、ホットスペアのHDDへと自動的に切り替わり、RAIDグループの再構築が行われる。一見すると、こうしたRAID 5+ホットスペアによる対応で十分なデータ保護強度を達成できるように感じられる。実際、RAIDグループを構成するHDDの台数が非常に少ない小規模のシステムではRAID 5でも許容できるケースがほとんどだ。しかし、大型のストレージシステムを管理している人々は、誰もが口を揃えて「RAID 5+ホットスペア程度のデータ保護ではまったく信頼できない」と話す。その理由は、RAIDグループの再構築中に何らかのトラブルを経験しているからである。
それと同時に問題なのが、後者のバッドブロックである。バッドブロックは、製品出荷後に使用環境によって自然に発生したり、ユーザーの日頃の取り扱いによって発生するアクセス不能なデータ領域を指す。HDDへのアクセス最小単位はセクタなので、バッドセクタと呼ばれることもある。HDD内部の機構もしくはRAIDコントローラを通じて、バッドブロックを正常なブロックに置き換える処理(background scrubs)がバックグラウンドで自動的に行われるが、これによってバッドブロックが完全になくなることはない。あくまでも、HDDへのアクセスが発生したときにバッドブロックに遭遇する確率を下げているだけなのだ。 バッドブロックなどによってHDDに格納されているはずのデータを読み出せない割合は、修復不能なリードエラー(unrecoverable read error rate)で示される。現在のHDDでは、SCSI/FC HDDが1015ビット(10万GB)の読み出しにつき1回以下、ATA HDDが1014ビット(1万GB)につき1回以下の割合で修復不能なリードエラーが発生する。ATA HDDの数字はSCSI/FC HDDの10倍とかなり大きいが、これは1セクタごとに割り当てられているエラー訂正用のECCビットがSCSI HDDよりも少ないからだ。HDDの設計段階において、SCSI/FC HDDは記憶容量を多少犠牲にしても信頼性を重視しているのに対し、ATA HDDはGB単価を下げるために記憶容量を重視していることを意味する。 ■ 決して安心できないRAID 5+ホットスペアの定番環境 次に、RAID 5の環境がどれくらい危険であるかを定量的に調べてみよう。ここでは、SCSI HDDとATA HDDに対し、RAIDグループを構成するHDDが少ない場合と多い場合の合計4つのパターンを考える。パターン1はSCSI HDDが5台、パターン2はSCSI HDDが50台、パターン3はATA HDDが5台、パターン4はATA HDDが50台である。SCSI HDDの記憶容量は73GB、MTBF(Mean Time Between Failures)は100万時間、修復不能なリードエラーは1015ビットの読み出しにつき1回、ATA HDDの記憶容量は300GB、MTBFは40万時間、修復不能なリードエラーは1014ビットの読み出しにつき1回とする。RAIDグループの再構築中に修復不能なリードエラーが発生する確率(F)は、RAIDグループ中でユーザーが使用可能な記憶容量をC、1GBあたりの修復不能なリードエラー率をλとすると、1-(1-λ)Cという数式で算出される。RAID 5のユーザー使用可能容量は「合計台数-1台分」であることから、Cはパターン1が292GB、パターン2が3577GB、パターン3が1200GB、パターン4が14700GB、またλはパターン1と2が10-5、パターン3と4が10-4となる。これらの数字からFを算出すると、パターン1が0.29%、パターン2が3.5%、パターン3が11%、パターン4が77%となる。HDDの台数が増えるとFも増大し、ATA HDDでは5台構成で10回の再構築中に1回、50台構成では実に4回の再構築中に3回もデータ損失が発生することが分かる。 さらに、すでに求めたF、HDDのMTBF、RAIDグループの構成台数(n)から、RAIDグループの再構築によってデータ損失が発生する時間間隔 MTTDL(Mean Time To Data Loss)を算出する。MTTDL=MTBF÷n÷F [時間] であることから、パターン1が7830年、パターン2が65年、パターン3が81年、パターン4が14カ月となる。パターン4は、実に1年ちょっとでデータが失われる可能性があることを示している。 今回の計算に用いたMTBFなどの値はあくまでも理論上の話であり、実際のHDDの故障率はこれよりも高いと考えた方が無難だ。また、2台のHDDが同時に故障するケースは含まれていないため、これを加えるとMTTDLはさらに短縮される。さらに、ストレージ管理者が故障していないHDDを誤って抜いたり、2台のHDDを同時に抜いてしまう可能性など、さまざまなヒューマンエラーも考慮に入れれば、RAID 5+ホットスペアという定番のデータ保護環境でも決して安全とはいえないのだ。先ほどの計算結果によれば、ATA HDDを多数束ねるような環境、例えばMAIDテクノロジ搭載のディスクサブシステムなどでは、より強固なデータ保護手法を導入しなければならないことが分かる。 ■ パリティを二重にとることでデータ保護強度を一気に高めるRAID 6 そこで、近年注目されているのがパリティを二重に持つデータ保護手法である。修復不能なリードエラーを含む、2台目のHDD障害からもデータを保護するには、パリティを二重にとればよいという発想から生まれたものだ。一般には、RAID 5にパリティを1台追加するという意味合いから、RAID 6やRAID 5+、RAID 5DPなどと呼ばれている。ただし、カリフォルニア大学バークレー校のDavid Patterson博士らが1988年に発表したオリジナルの論文では、RAIDレベルとして1から5までの5種類しか定義されていない。冗長情報の多重化について取り上げた論文は、Patterson氏らの「How reliable is a RAID?(IEEE Spring COMPCON, 1989)」以降、いくつか見受けられるようになった。Garth A. Gibson氏の「Redundant Disk Arrays: Reliable, Parallel Secondary Storage(MIT Press, 1992)」やW. Burkhard氏らの「Disk Array Storage System Reliability(23rd Annual International Symposium on Fault-Tolerant Computing, June 1993)」がその代表例だ。Burkhard氏らの論文には“より大容量のディスクアレイでは、2台以上のHDDに障害が発生する可能性があり、RAIDグループにはより強力な冗長コードを必要とする”と書かれている。これは、まさにRAID 6を示唆する表現だ。 さて、次にRAID 6の仕組みを説明しよう。基本的には、RAID 5にパリティをさらに1つ追加する形となるが、そのパリティの取り方として2D-XORとP+Qの2通りがある。
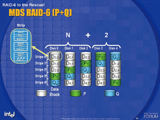
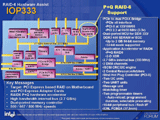
2D-XORは、物理的に直交関係にあるパリティを2つとる方式だ。従来のRAID 5と同様にローテーションさせながらの水平パリティ(horizontal parity)に加え、複数のHDDとストライプをまたがる斜め方向のデータを加算した対角パリティ(doagonal parity)を専用のHDDに格納する。この方式は単純な加算(XOR演算)のみで完結するのが利点だが、書き込み性能はあまり高くない。というのも、1カ所のブロックを書き換えただけで、複数の斜めパリティを再計算し直さなければならないからだ。2D-XORで書き込み性能を高めるにはライトバックキャッシュを強化し、ある程度まとまった単位でパリティの再計算を行い、同時にデータとパリティの書き込みを行うように工夫する必要がある。 P+Qは、数学的に直行関係にあるパリティを2つとる方式だ。パリティ生成のエンコード方式としてMDS(Maximum Distance Separable)符号を使用する。通常は、MDS符号の中でも他のテクノロジで採用実績の豊富なリードソロモン符号が用いられる。具体的には、PパリティはRAID 5と同じくデータ間の加算で生成されるが、Qパリティはこれらのデータに何らかの係数で重み付けをしてから加算を行う形となる。これにより、2つのデータが失われたときには、不明な2つの解を求める連立一次方程式に帰着する。 P+Qの利点は、2つのパリティをすべてのHDDに対してローテーションさせているため、HDDに対するアクセス負荷が均一にかかることである。特に書き込みは2D-XORよりも高速になることから、最近ではP+Qを採用している製品がほとんどだ。一方、欠点は2D-XORよりも計算量が多いことで、RAID 6に最適化された専用ハードウェアによるオフロードが不可欠である。ただし、今年2月にはIntel IOP333/331 I/O ProcessorのようなRAID 6対応の汎用I/Oプロセッサも登場しており、今後は安価なディスクサブシステムやRAIDカードでもRAID 6を実装するケースが増えてきそうだ。
■ デュアルパリティを採用したディスクサブシステムが次々と登場 RAID 6は、その複雑さゆえに当初は理論で唱えられているに過ぎなかったが、1994年になるとようやく実際の製品が姿を現した。その第一弾が、StorageTekの仮想ディスクサブシステム「Iceberg 9200」である。Iceberg自体は1991年にそのコンセプトが発表されていたが、マイクロコードの開発にかなり手間取り、実際の製品が登場したのは1994年だった。Icebergは、RAID 5と同様の水平パリティに加え、リードソロモン符号によって斜め方向の対角パリティをとる2D-XORを採用していた。StorageTekは、Icebergの登場以来、最新のFlexLine V2X2 SVA(Shared Virtual Array)に至るまで、すべての仮想ディスクサブシステム製品でRAID 6をサポートしている。ちなみに、FlexLine V2X2 SVAはパリティの取り方としてP+Qを採用している。その他、RAID 6への対応を強く打ち出している製品としては、Hewlett-PackardのHP StorageWorks Virtual Arrayがある。ただし、HPは“パリティを二重にとる”という点を強調して、RAID 6ではなくRAID 5DP(Dual Parity)と呼んでいる。また、2Uや3Uサイズという小型のディスクサブシステムでRAID 6のサポートも急速に進んでいる。例えば、Tekram SystemsのTekram-U/FCシリーズ、サイバネテックのPhoenix16シリーズ、日本コンピューティングシステム(JCS)のJCS VCRVALシリーズなどがその代表例だ。 これらの製品は、安価ながらSCSI/FC HDDよりも故障率がどうしても高いATA HDDを“より安全に”使用するためにRAID 6を採用している。エンタープライズ分野では、ミッションクリティカルな用途にも対応できる高い信頼性が求められるが、同時にコスト削減に対する要請もかなり強く、ATA HDDが積極的に採用されているという背景がある。SCSI/FCは高信頼、ATAは低信頼の環境で使い分けるという従来の考え方はもはや通用しないのだ。ATA HDDを使用する最近のエンタープライズストレージでは、ATA HDDの弱みをうまく補完できるRAID 6が威力を発揮する。
一見すると、RAID 4と2D-XORの組み合わせは低速なようにも感じる。しかし、NetAppはこれらの問題をWAFL(Write Anywhere File Layout)と呼ばれるファイルシステムとNVRAM(不揮発性RAM)によって解消している。ディスクサブシステムに対してデータを書き込むと、いったんNVRAMに書き込まれ、即座に書き込み完了の応答(コミット)が返される。このため、ユーザーの体感速度は非常に高速だ。NVRAMに書き込まれたデータは、10秒ごと、もしくはNVRAMが一定量に達した時点でディスクに書き込まれる。すでに2D-XORの実装にはライトバックキャッシュが重要だと書いたが、これに相当するのがNVRAMである。また、WAFLはデータ更新の際に同じディスクブロックを上書きしない追記型構造(フルジャーナル型)をとっているため、RAID 4との親和性が高い。こうした理由から、RAID 4+2D-XORという構成であっても他社のRAID 5DP、RAID 6に匹敵するアクセス性能を達成しているのだ。 ■ 関連記事 ・ 「2台のHDDが同時に故障してもデータが守られる」RAID 6対応ストレージ(2004/07/21) ・ 日本NetApp、同社のエンタープライズ向け戦略を支える製品群を発表(2003/12/09) ・ サイバネテック、RAID 6に対応したストレージを発表(2003/10/14)
( 伊勢 雅英 )
|